
Database: redisearch 2.0 is looking for flash memory and worldwide

Redis labs has after a fun-month previewphase redisearch 2.0. The release brings a complete overarched architecture that simplifies the creation of secondary indices and a global distribution. In addition, she can use the multilayer memory concept of redis on flash. The blog post promises a performance increase by a factor of 2.4 against redisearch 1.X.
Distributed worldwide
So far, the index of redisearch in the keyspace, an internal directory, stored in the redis all key. This is different in version 2.0, so that the search also works in geographically distributed databases according to the principle of active active geo distribution, which sets conflict-free replicated types (crdts). The latter avoids conflicts that can occur through changes in distributed data.
With the new architecture, redisearch pursues the change of the hashes after replicating the data, making the indexes of the distributed redisearch instances to be consistent.
The removal of the index from the keyspace means for developers that no longer function calls that use the index key. The new command is ft as a replacement._list, which lists all indexes of the database. In addition, each index now requires a prafix or a filter to determine which documents redisearch should automatically index.
Looking for: cold, warm, hot
It is also new that redisearch is using redis on flash (rof). The database does not save the entire record in the dram. Instead, only the keys, the associated redis dictionary and the most important data (hot values) are instead. The less used records (warm values) stores the database on local ssds.
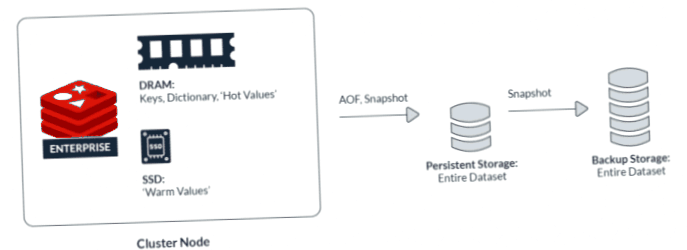
Rof stores only the rigid work data in the dram and sets the remaining data sets on flash memory.
Flexible index
An essential architectural approach concerns the index, whose writing process is now over hset instead of as before about ft.Add. The system returns the order of writing to the database and the index. Redisearch pursues the hashes of the written data and writes changes in synchronism into your own index.
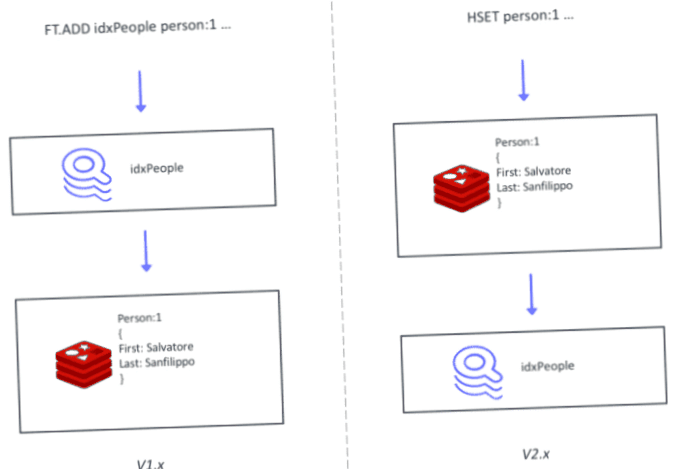
Redisearch 2.0 brings a new architecture with the letter from the index.
The synchronization of the index remotes the migration of the data for redis databases. This should allow the search module to be easier and attached to existing instances during operation.
In the course of the changeover to the new architecture, redis labs has mapped all ft commands on the respective counterparts in redis: ft.Add to hset, ft.Del on del, ft.Get on hgetal and finally ft.Mget on hgetal. This should appropriate 1.X applications with redisearch 2 without any changes.
Several instances for open source
The open source variant of redisearch 2 is unlike version 1.X does not limit to a shard. The rscoordinator for managing a distributed search is available on github. The module is under the redis source available license (rsal), which had introduced redis labs in the course of the changeions of licensing policy in early 2019.
Further details can be found in the redis blog and the official press release. In september 2020, redis labs has a blog post for introduction in the use of redisearch 2.0 published, and a tutorial is found on github.